Py学习记录
Python 常规学习
Python学习笔记(一)
Python学习笔记(二)
Python学习笔记(三)
Python学习笔记(四)
Python学习笔记(五)
Python学习笔记(六)
Python学习笔记(七)
Python习题(一)
Python习题(二)
Python习题(三)
Python习题(四)
Python习题(五)
Python常见Bug
Python编程环境
Python-依赖安装(三方库)
Python-VS Code
pip-换源
py 程序转 exe
Python-打开选择文件对话框
Python 项目
Python-密码学
Python-与佛伦禅
Python-喵语翻译
Python-翻译服务器
Python-邮件发送
Python-自动签到
Python-自动签到(Post请求)
Python-自动签到(模拟操作)
Python-图片添加二维码
Python-数据可视化
Python-端口扫描器
Python-未测试项目
Python-虚拟环境
Python-临时环境
Python-venv虚拟环境
Python-Conda
Python-OpenCV
OpenCV-人脸识别
Python-PyTorch
本文档使用 MrDoc 发布
-
+
首页
Python学习笔记(七)
## 初见HTML 【看懂】:我们看懂了 HTML 代码,就可以运用“python”从网页结构中提取出我们想要的数据 【修改】:在读懂HTML代码后,我们可以在浏览器中修改当前显示的网页结构 HTML(Hyper Text Markup Language)是用来描述网页的一种语言,也叫超文本标记语言。 换种说法,HTML和网页的关系,就像汽车设计图纸和汽车的关系 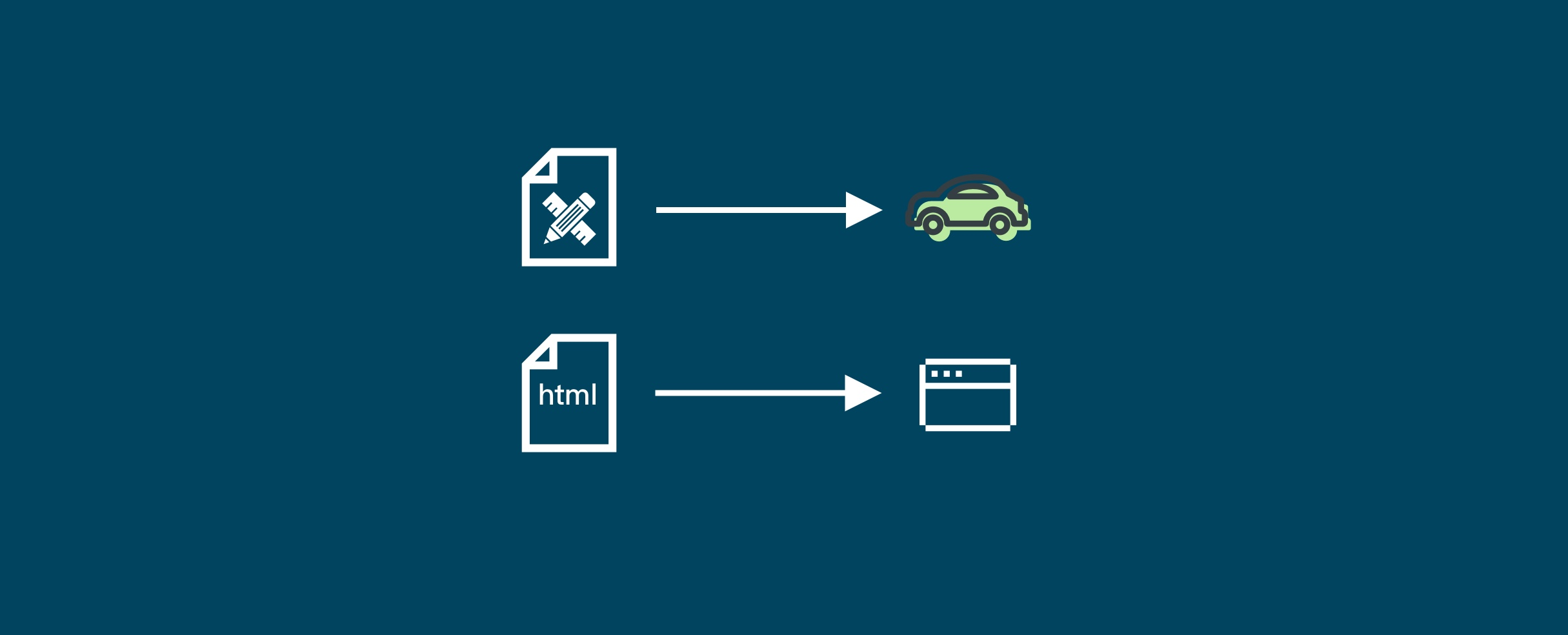 HTML是前端工程师使用的语言,用来设计“网页的结构图”。 浏览器会把HTML解析成我们看到的网页。 ### 如何查看网页的HTML代码 打开任意一个网站,如:https://www.baidu.com/ 在网页空白处右键,查看网页源代码 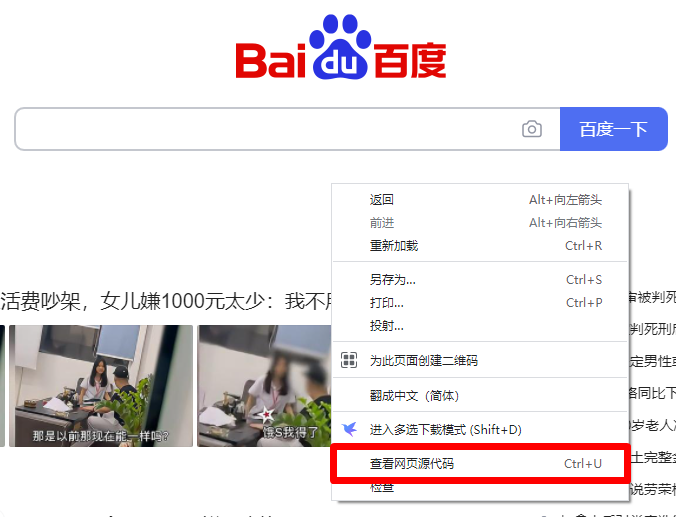 浏览器新开的标签页就是HTML源码了 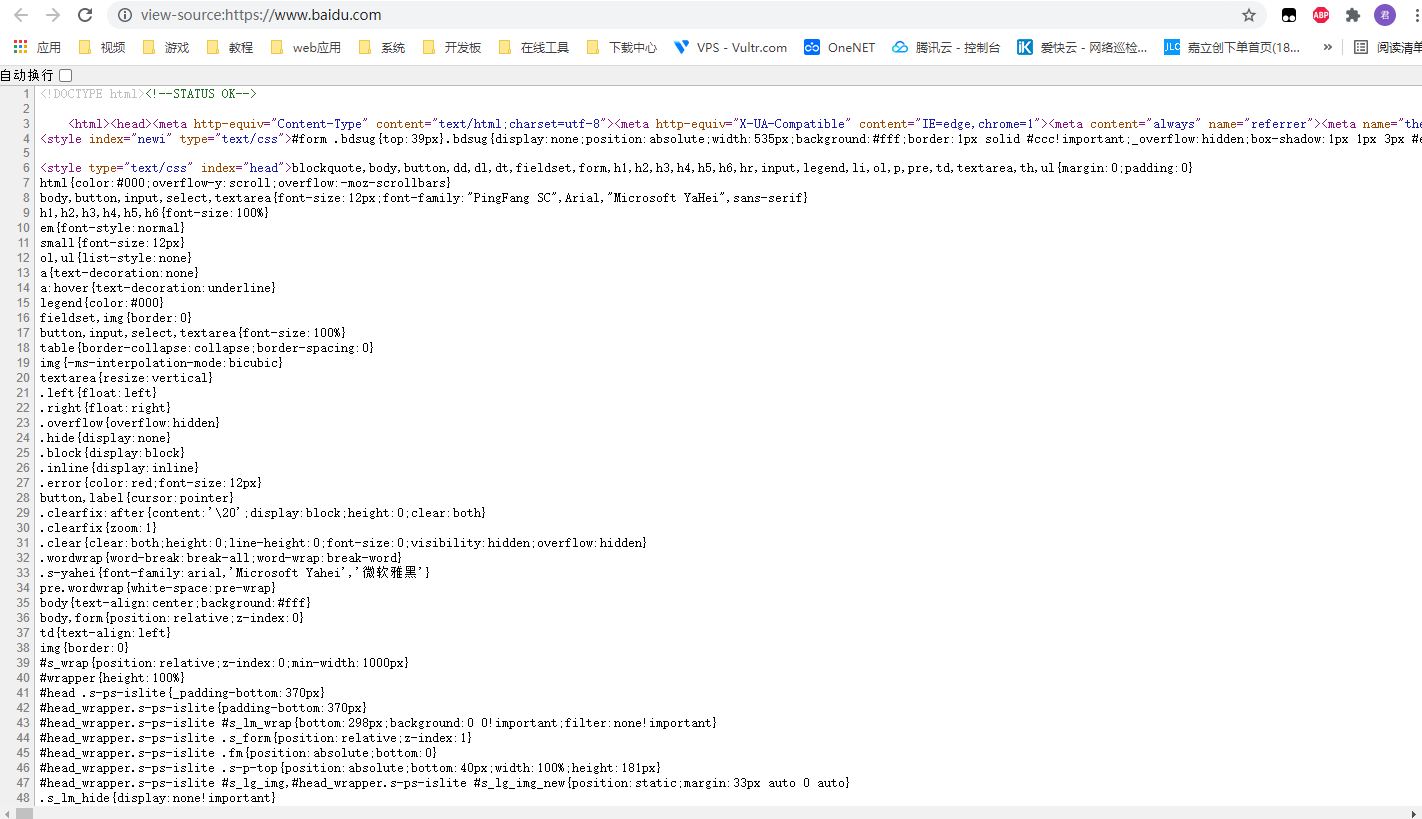 不过整个网页代码量都很大,查看起来很费劲 这时候就可以使用`开发者工具`来辅助查看了 一般默认快捷键为 <kbd>F12</kbd> 或是 <kbd>Ctrl</kbd>+<kbd>Shift</kbd>+<kbd>I</kbd> 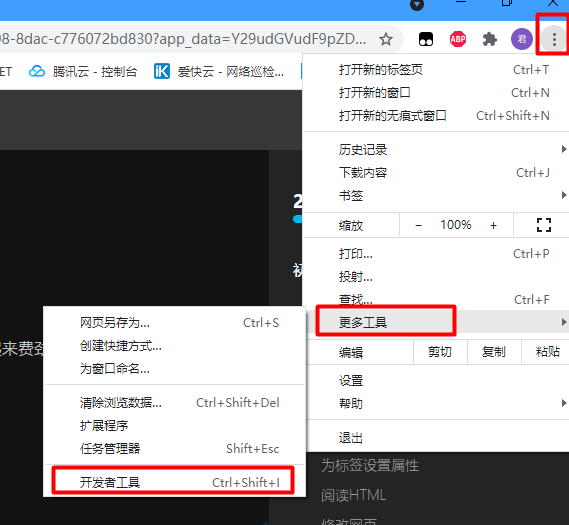 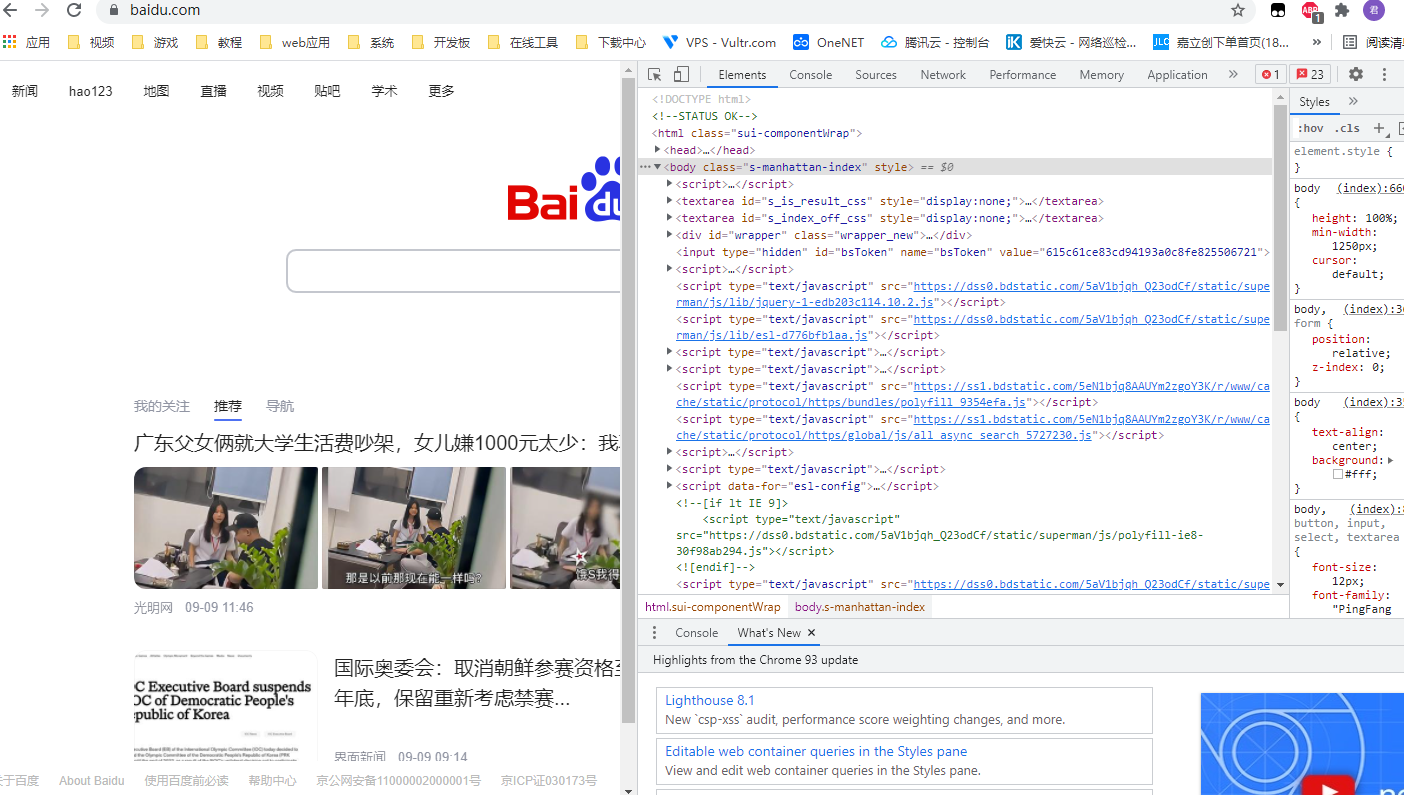 鼠标停留在代码上,相应位置会高亮,通过代码找页面元素 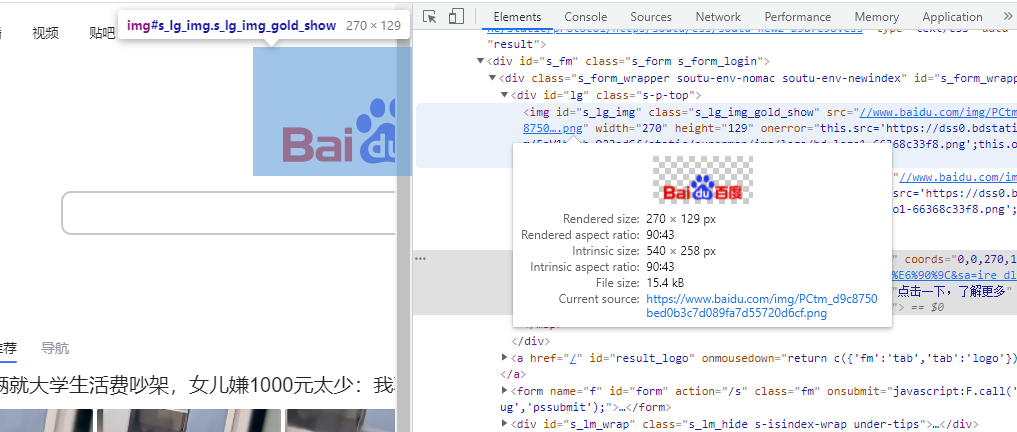 也可以使用这个,通过页面元素反向查找代码 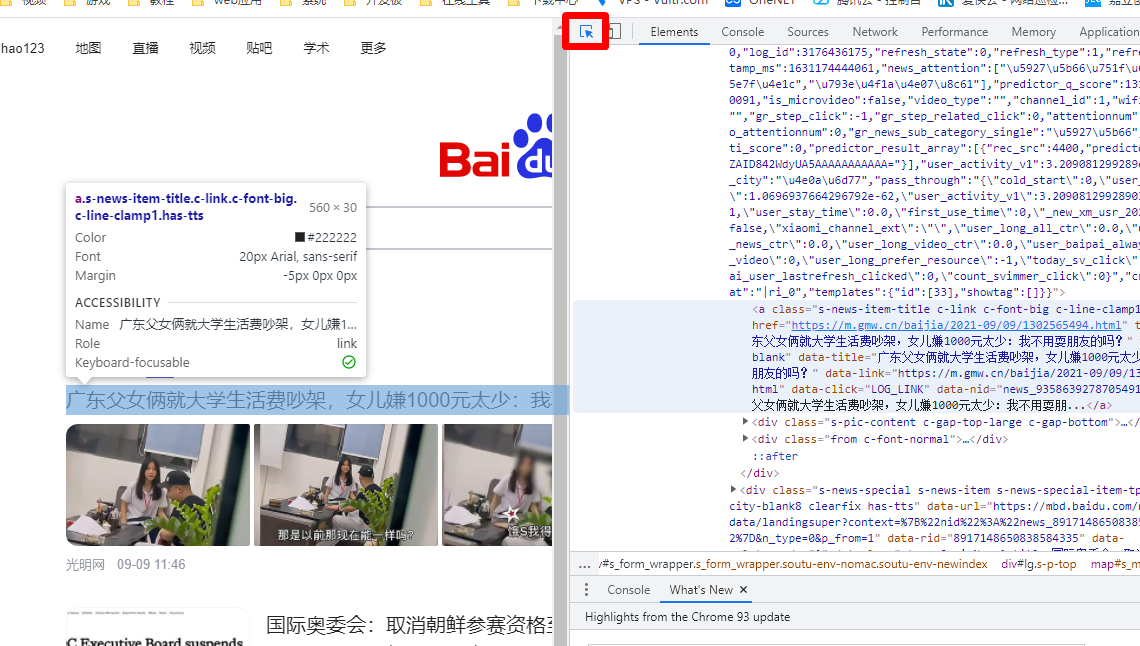 ### HTML的层级 先以汽车为例,车子由很多的零部件组成,图纸会描述出每个零部件的大小,放置的位置,功能等等。同时整个车子还会分很多区域,发动机舱,座舱,这些区域中又会有各种零件 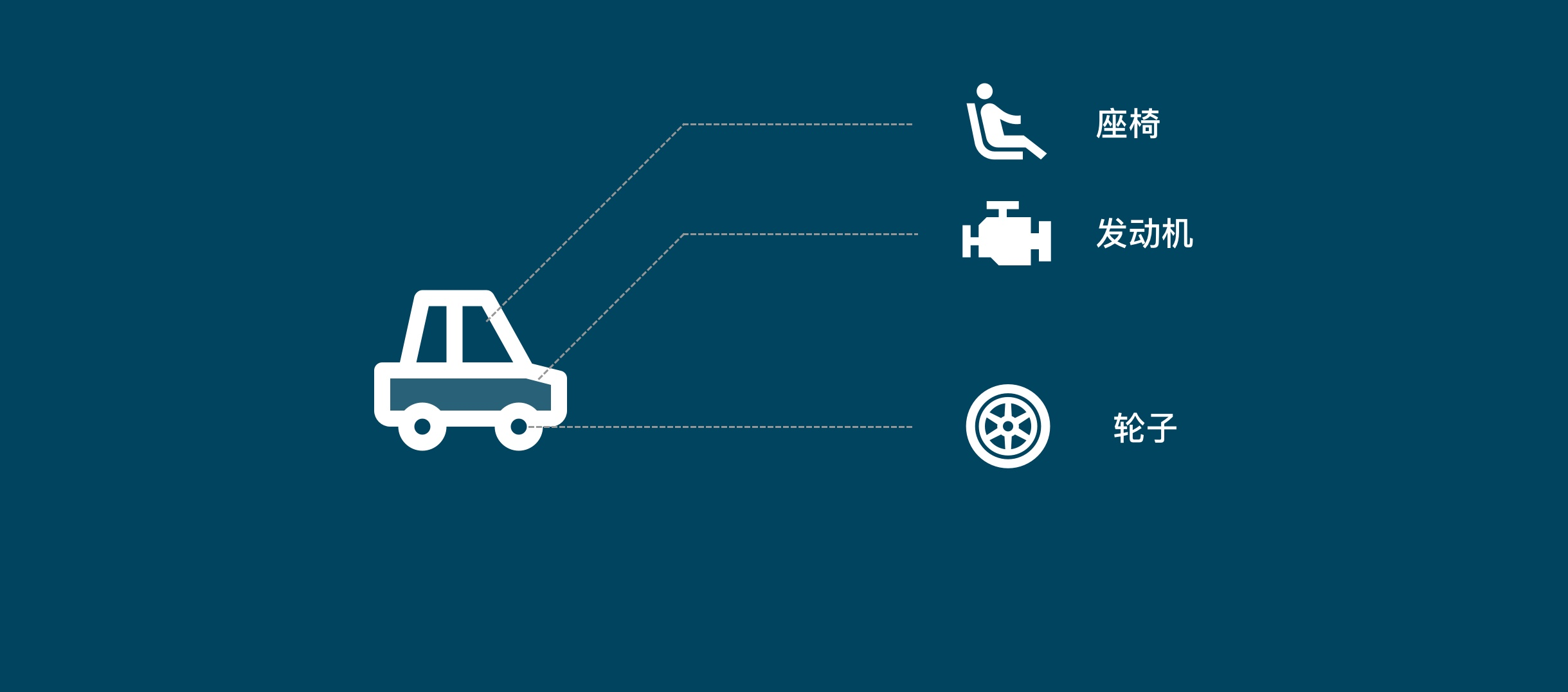 在HTML中,每段代码都有它自己对应的功能 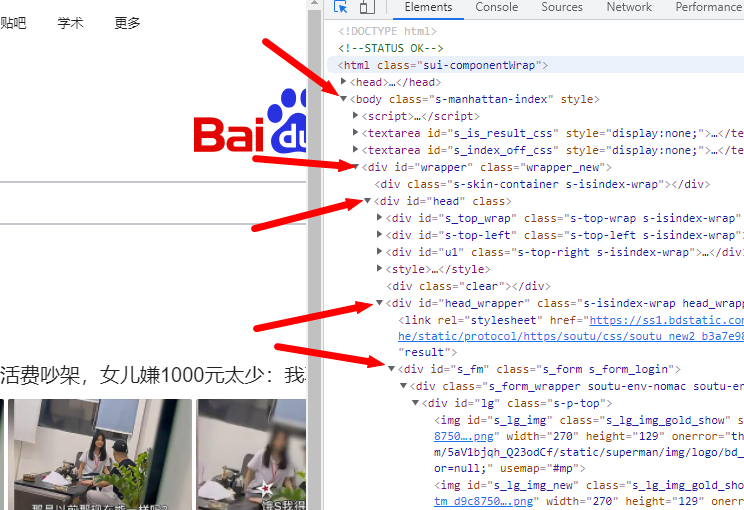 当你点击代码中的一些三角形的时候,可以展开和合上对应的一段代码。这就是HTML里面的层级关系 这每一个可以展开和合上的小三角形里包含的内容,都是一个层级,它很像电脑中一层一层的文件夹 ## 学习HTML 创建一个简单HTML,通过这段代码学习一下HTML的结构 保存成`.html`格式就可以了 ```Html <html> <head> <meta charset="utf-8"> </head> <body> <h1>我是一级标题</h1> <h2>我是二级标题</h2> <h3>我是三级标题</h3> <p>我是一个段落啦</p> </body> </html>xa0 ``` 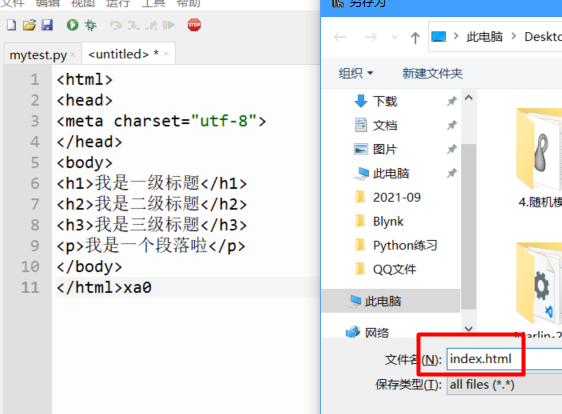 保存后,双击打开就行 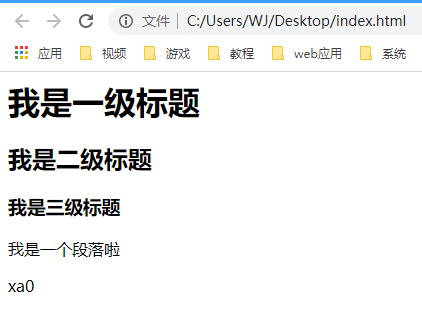 可以看到很多的 <> 尖括号,尖括号里面包含的字母,就是「标签」。我们可以看到标签都是成对出现,前面的是「开始标签」,后面的带有斜杠的就是「结束标签」 但是也有少部分单个出现的标签,比如上面那段代码中的<meta>,它定义了网页的编码格式为utf-8  开始标签+标签中的内容+结束标签就组成了「元素」。  HTML中最常用的5大元素:  HTML标签是可以嵌套标签的。就像俄罗斯套娃一样,一个娃娃里面套着另一个娃娃 ### \<head>和\<body> \<head>元素就是网页头,\<body>元素就是网页体。他们构成了HTML的基本结构。 是不是听起来很像人体结构,人体也是由头部和身体组成的。  HTML的元素和网页的内容是对应的。 但是「网页头」是不会显示在网页中的,你在网页上看到的内容都是写在「网页体」里面的。 ```Html <head> <meta charset="utf-8"> <title>title标签里面包含的就是网页的名字</title> </head> ``` 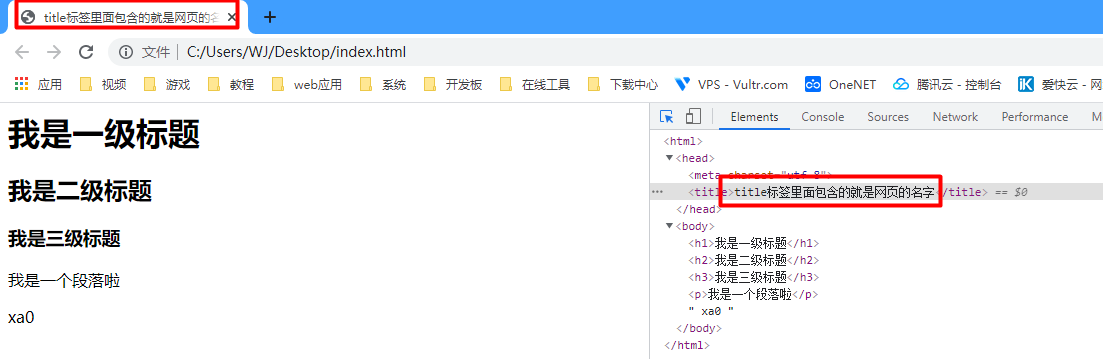 \<meta>标签定义了这个网页的编码格式。 \<title>元素就是用来设置这个网页的标题,会显示在浏览器的选项卡上 所有写在`<head>`标签中的标签元素都`不会显示`在网页的内容中 只有把标签元素写在`<body>`,也就是网页体中,才可以在网页中`显示`出来 ### 为标签设置属性 ```Html <html> <head> <meta charset="utf-8"> <title>我是标题2.0</title> </head> <body> <h1 style="color:#ff0000;">造物者W</h1> <a href="http://nas.zwzw.xyz:8090" target="_blank">点这里去官网看看</a> <br> <h2>学习ing</h2> <p>学习不是一蹴而就的</p> </body> </html> ``` 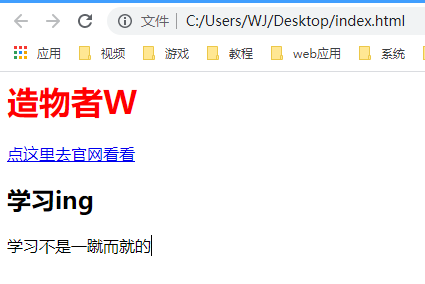 \<h1>标签的颜色发生了改变;然后添加了一个博客的链接 这些都是靠「属性」来完成的 特别注意!`HTML的属性和我们之前学的Python属性完全不是一个东西` 通过HTML属性,我们可以给标签设置各种信息 #### 文本样式 给\<h1>标题添加了“style”属性,在这个属性中,我们设置了文字的“color”,也就是文字的颜色 ```Html <h1 style="color:#ff0000;">造物者W</h1> ```  style属性可以用来给文本类的标签定义样式,包括但不限于字体,字体颜色,字体大小,字体间距,文字对齐方式 `属性都在HTML的开始标签中设置`的,在`结束标签中设置属性是不会生效`的 #### 超链接 \<a>标签的用途就是定义链接,搭配上“href”属性,它用来规定链接的URL。所以你点击它的话,就可以直达规定的URL地址啦 ```Html <a href="http://nas.zwzw.xyz:8090">我是可以跳到官网的一个链接,点我试试</a> ``` #### class ``` <html> <head> <meta charset="utf-8"> <title>我是标题2.0</title> <style> .menu{ /*以下是.book的具体样式规定*/ float: left; /*控制元素浮动*/ margin: 5px; /*外边距为5像素*/ padding: 15px; /*内边距为15像素*/ width: 300px; /*宽度为350像素*/ height: 250px; /*高度为240像素*/ border: 3px solid #ff0000; /*边框为3像素,颜色为ff0000*/ } </style> </head> <body> <h1 style="color:#ff0000;">造物者W</h1> <h3>推荐菜:</h3> <a href="http://nas.zwzw.xyz:8090" target="_blank">点这里去博客看看</a> <div class="menu"> <h2>米粉蒸肉</h2> <p>米粉蒸肉,是江西省特色名菜,属于赣菜系列,当地人每年立夏前后都喜欢蒸上一碗米粉蒸肉,据说吃了不会生痱子。2018年9月,被评为“中国菜”之江西十大经典名菜 </p> </div> </body> </html> ``` 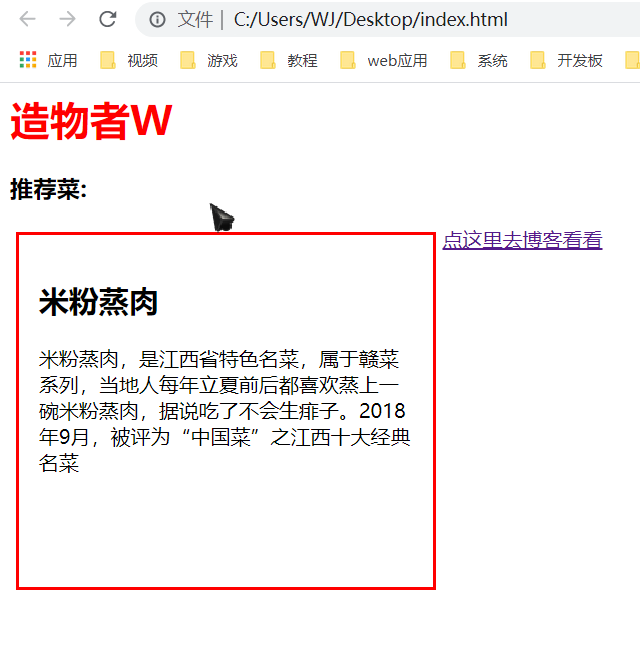 \<head>标签中加入了一个 \<style> 标签,里面的内容就是对拥有“.menu”这个属性的标签进行样式的规定 “style”中就是网页布局的描述,上面代码中的注释都写清楚了对应代码的用处。比如说“border: 3px solid #ff0000”的意思就是加一个边框,宽度为3个像素,颜色为#ff0000: 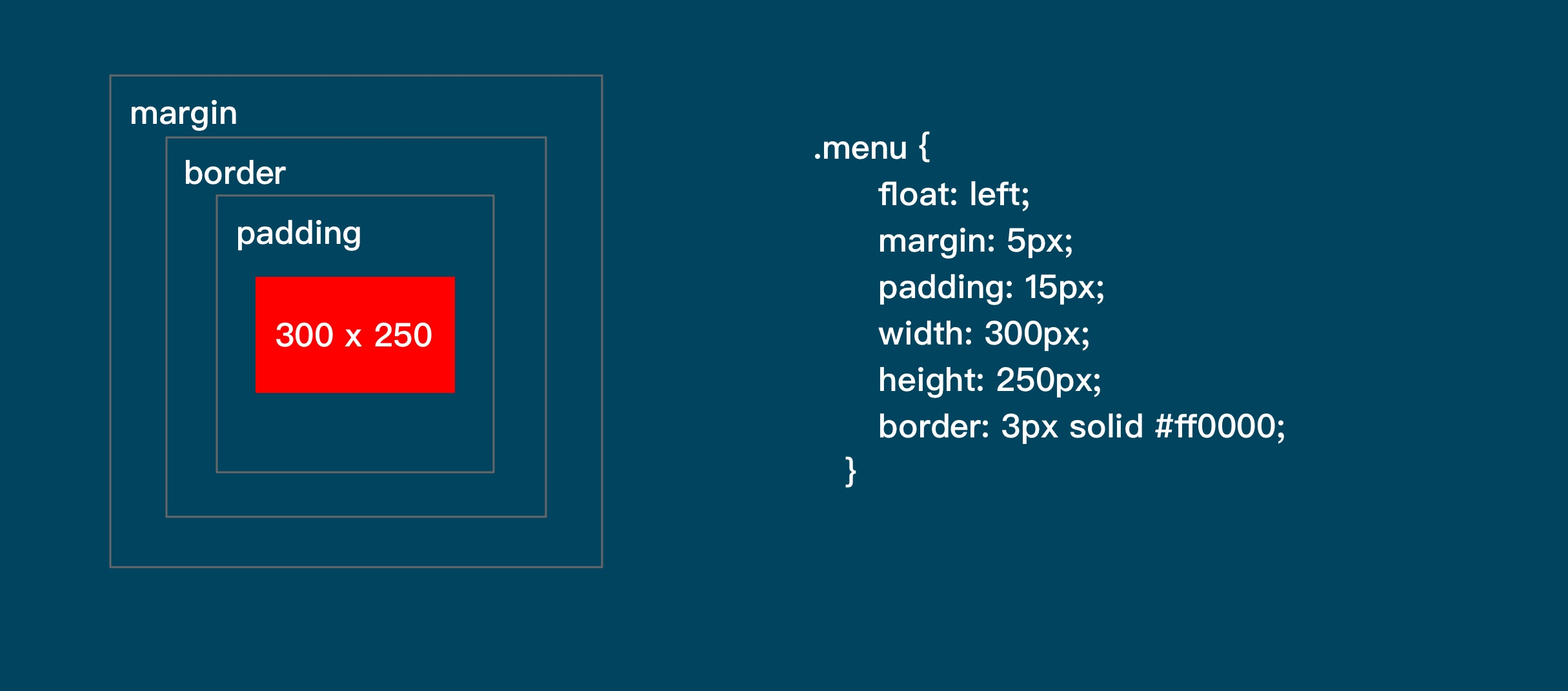 有两个地方出现了“.menu”,一个是\<head>里面的,一个是米粉蒸肉外层的\<div class=“menu”> 点“.”代表了一个class。那么“.menu”就代表了一个叫做“menu”的“class” 在\<head>的\<style>中,我们定义了一个“class”叫做“menu”,然后下面的大串样式代码是对“menu”这个“class”的属性描述,\<body>中的\<div>标签定义它的“class”=“menu”就是调用这个class类应用定义的属性 在装修设计中也很常见。比如说同一个尺寸的房门会装在各个房间,设计图上统一用“Door01”来表示,在统一的地方定义“Door01”的尺寸参数  在HTML中,“class”属性可以被多个不同的标签使用 再利用这个class类添加一组数据 ``` <html> <head> <meta charset="utf-8"> <title>我是标题2.0</title> <style> .menu{ /*以下是.book的具体样式规定*/ float: left; /*控制元素浮动*/ margin: 5px; /*外边距为5像素*/ padding: 15px; /*内边距为15像素*/ width: 300px; /*宽度为350像素*/ height: 250px; /*高度为240像素*/ border: 3px solid #ff0000; /*边框为3像素,颜色为ff0000*/ } </style> </head> <body> <h1 style="color:#ff0000;">造物者W</h1> <h3>推荐菜:</h3> <a href="http://nas.zwzw.xyz:8090" target="_blank">点这里去博客看看</a> <div class="menu"> <h2>米粉蒸肉</h2> <p>米粉蒸肉,是江西省特色名菜,属于赣菜系列,当地人每年立夏前后都喜欢蒸上一碗米粉蒸肉,据说吃了不会生痱子。2018年9月,被评为“中国菜”之江西十大经典名菜 </p> </div> <div class="menu"> <h2>三杯鸡</h2> <p>三杯鸡是江西省地方传统名菜,相传与民族英雄文天祥有关。因烹制时不放汤水,仅用米酒一杯、猪油或茶油一杯、酱油一杯,故得名。 这道菜通常选用三黄鸡等食材制作,成菜后,肉香味浓,甜中带咸,咸中带鲜,口感柔韧,咀嚼感强 </p> </div> </body> </html> ``` 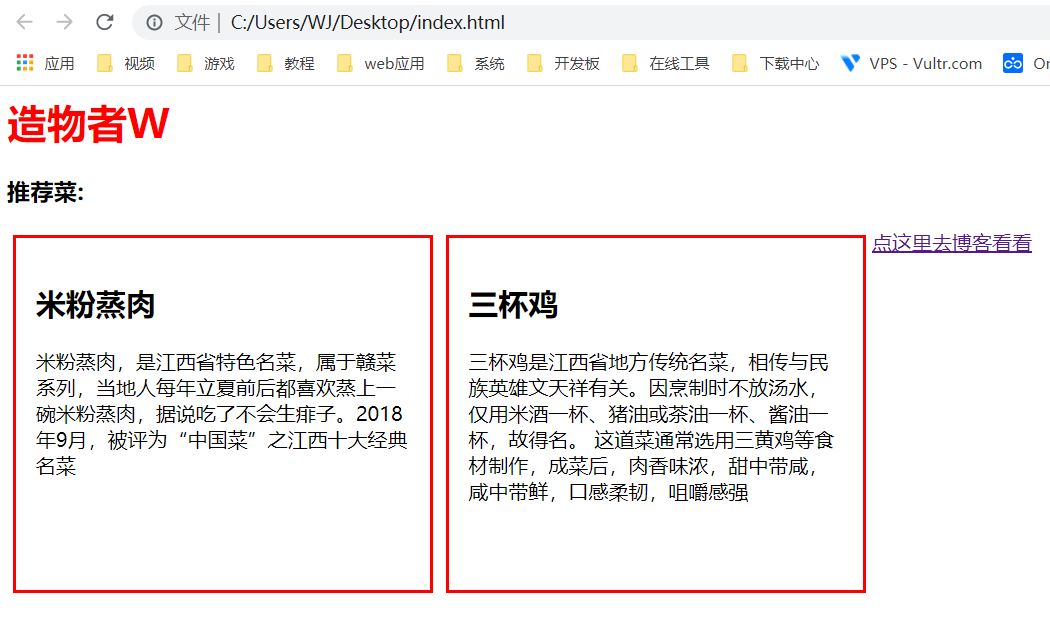 #### id id属性和class属性的用法类似,它们的目的都是为了查找、定位元素,或者为元素设置样式 `id`属性用于标识`「唯一」`的元素,而`class`用于标识`「一系列」`的元素  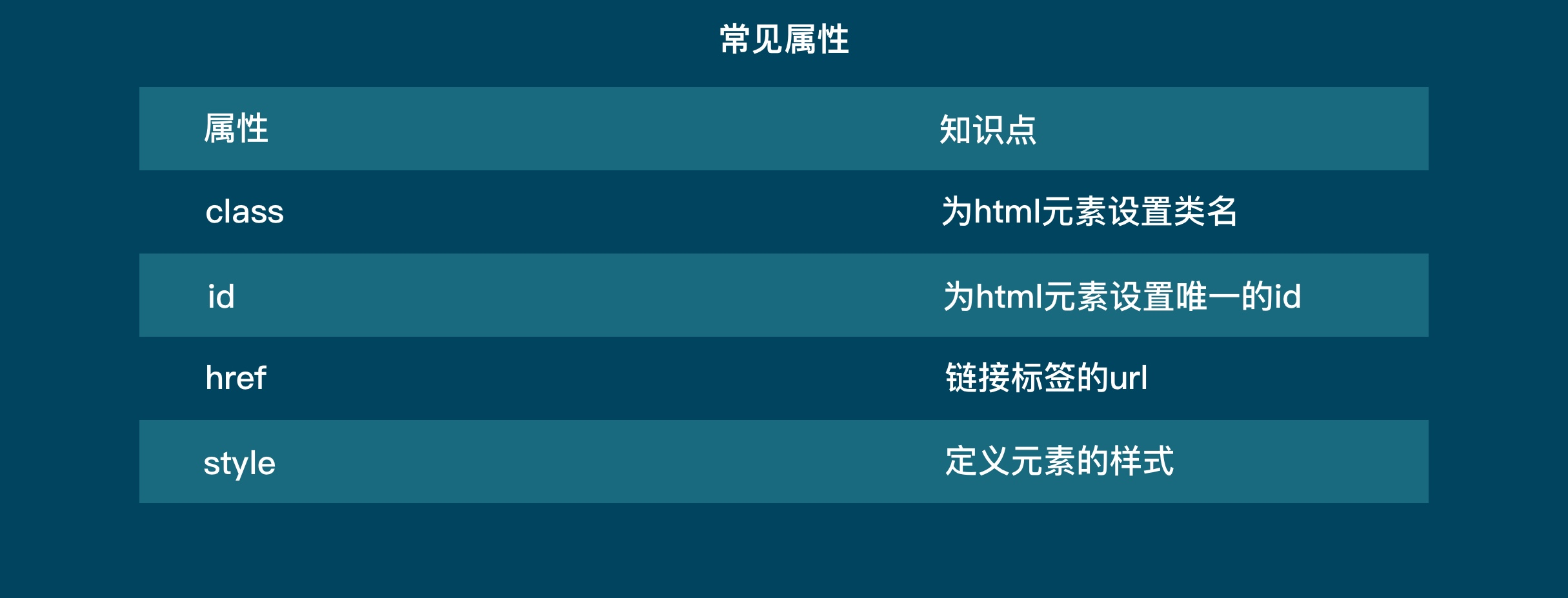 ### 阅读HTML  网页体有三大部分,\<header>\<section>\<footer>,分别对应了我们看到的网页的头部,中间内容,底部 ### 修改网页 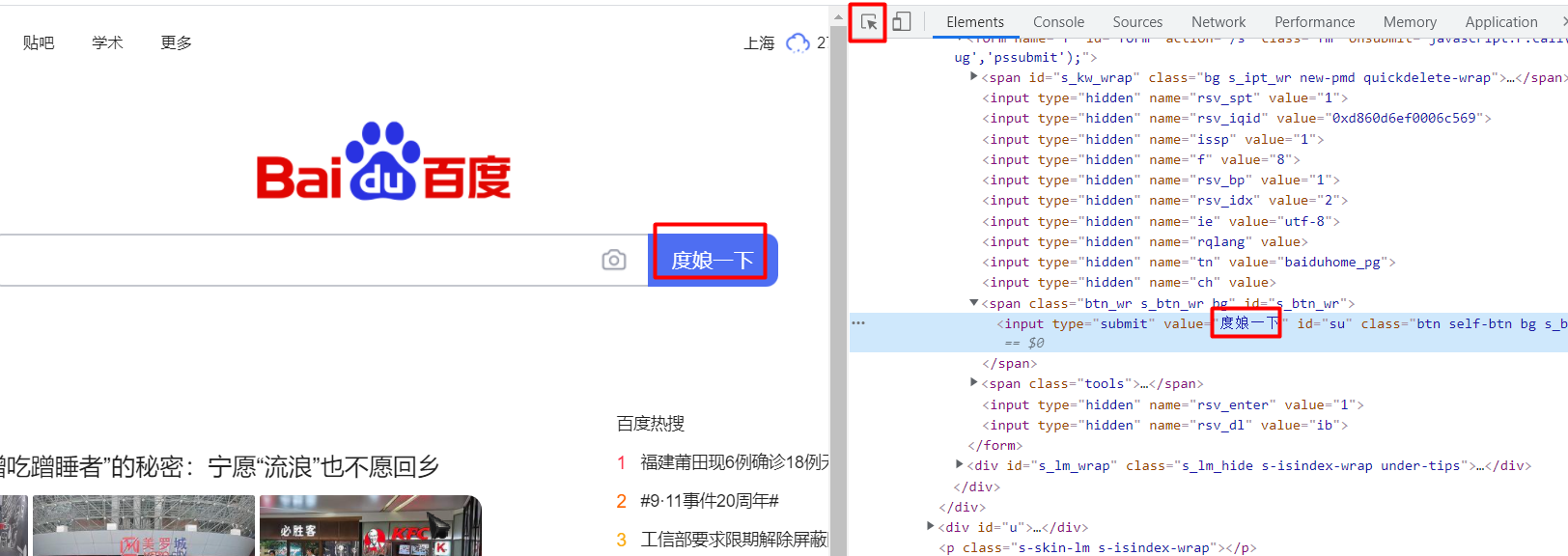 我们可用通过开发者工具,简单修改一下当前页面对应的源代码 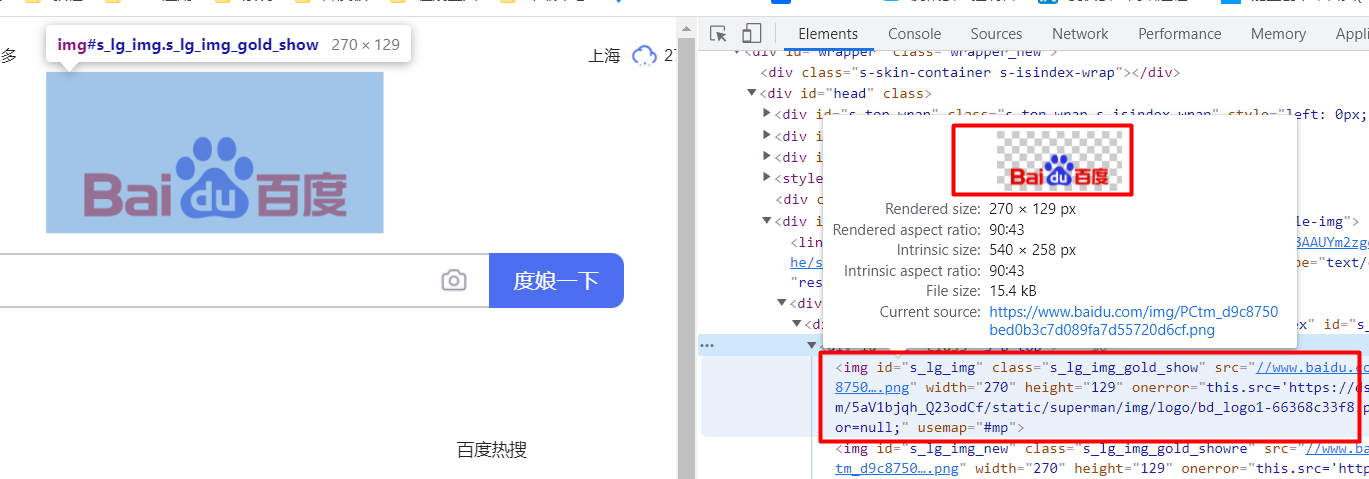 鼠标停留在代码还能显示对应元素 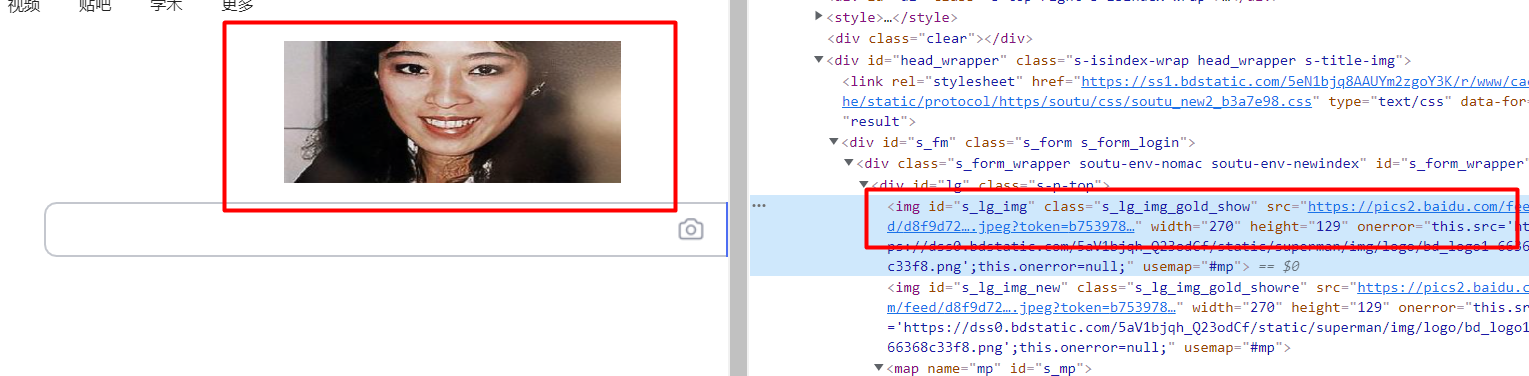 但是这种只能修改的只是本地页面的源代码,无法影响网页所在的服务器的源代码,刷新一下页面就会恢复原状 ### 用爬虫从HTML提取数据 通过“requests.get()”来获取的网页源代码 ``` import requests res = requests.get('https://xiaoke.kaikeba.com/example/canteen/index.html') print(res.text) ```  获取网页源码并保存到本地 ``` import requests # from kkb_tools import open_file res = requests.get('https://xiaoke.kaikeba.com/example/canteen/index.html') html=res.text #把Response对象的内容以字符串的形式返回 k = open('menu.html','a+',encoding='utf8') #创建一个名为 menu 的html文档,指针放在文件末尾,追加内容 k.write(html) #写进文件中 k.close() #关闭文档 # open_file('menu.html') ``` 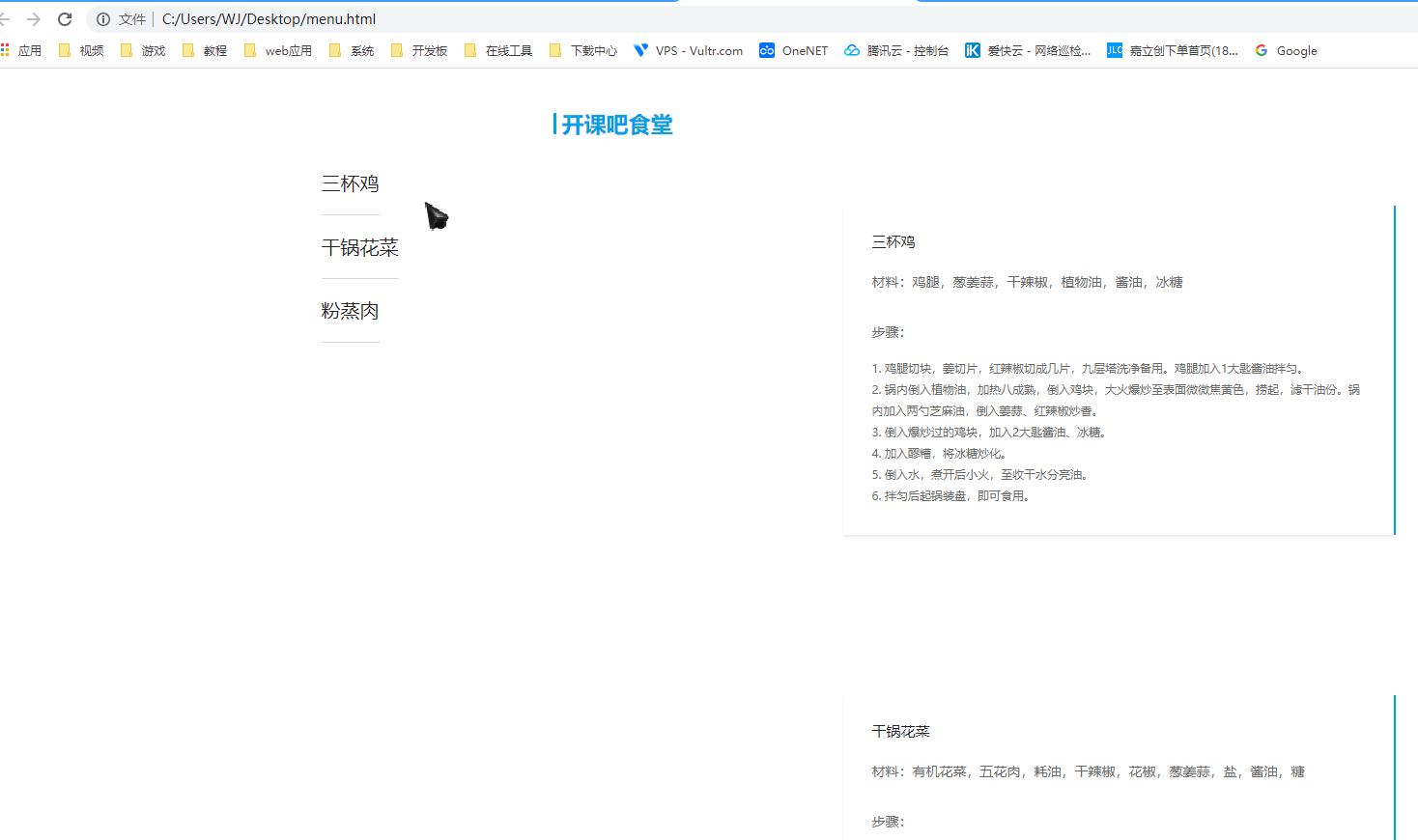
造物者W
2023年2月10日 12:26
转发文档
收藏文档
上一篇
下一篇
手机扫码
复制链接
手机扫一扫转发分享
复制链接
Markdown文件
分享
链接
类型
密码
更新密码